
Kali ini saya akan menjelaskan mengenai Parallel Computing yang tentunya akan dikupas secara tuntas. Pernahkah kalian mendengar istilah tersebut? apa sih itu? apa sejarahnya? bagaimana cara kerjanya? dan lain-lainya. untuk itu mari kita bahas satu per satu.
#AnbiyaShafardhiawanRizqullah
#4IA19
#ParallelComputation
#Parallelism Concept
#DistributedComputing
#ArchitecturalParallelComputer
#PengantarThreadProgramming
Apa itu Computing?

Kalo Pararel itu Sendiri Apa Sih?

Jadi Pararrel Computing itu Apa?

Pararrel Computing atau Komputasi paralel adalah salah satu teknik melakukan komputasi secara bersamaan dengan memanfaatkan beberapa komputer secara bersamaan. Biasanya diperlukan saat kapasitas yang diperlukan sangat besar, baik karena harus mengolah data dalam jumlah besar ataupun karena tuntutan proses komputasi yang banyak. Untuk melakukan aneka jenis komputasi paralel ini diperlukan infrastruktur mesin paralel yang terdiri dari banyak komputer yang dihubungkan dengan jaringan dan mampu bekerja secara paralel untuk menyelesaikan satu masalah. Untuk itu diperlukan aneka perangkat lunak pendukung yang biasa disebut sebagai middleware yang berperan untuk mengatur distribusi pekerjaan antar node dalam satu mesin paralel. Selanjutnya pemakai harus membuat pemrograman paralel untuk merealisasikan komputasi.

- Algoritma
- Bahasa Pemrograman, dan
- Compiler
Apa Tujuannya?

Tujuan utama dari pemrograman paralel adalah untuk meningkatkan performa komputasi. Semakin banyak hal yang bisa dilakukan secara bersamaan (dalam waktu yang sama), semakin banyak pekerjaan yang bisa diselesaikan. Analogi yang paling gampang adalah, bila anda dapat merebus air sambil memotong-motong bawang saat anda akan memasak, waktu yang anda butuhkan akan lebih sedikit dibandingkan bila anda mengerjakan hal tersebut secara berurutan (serial). Atau waktu yg anda butuhkan memotong bawang akan lebih sedikit jika anda kerjakan berdua.
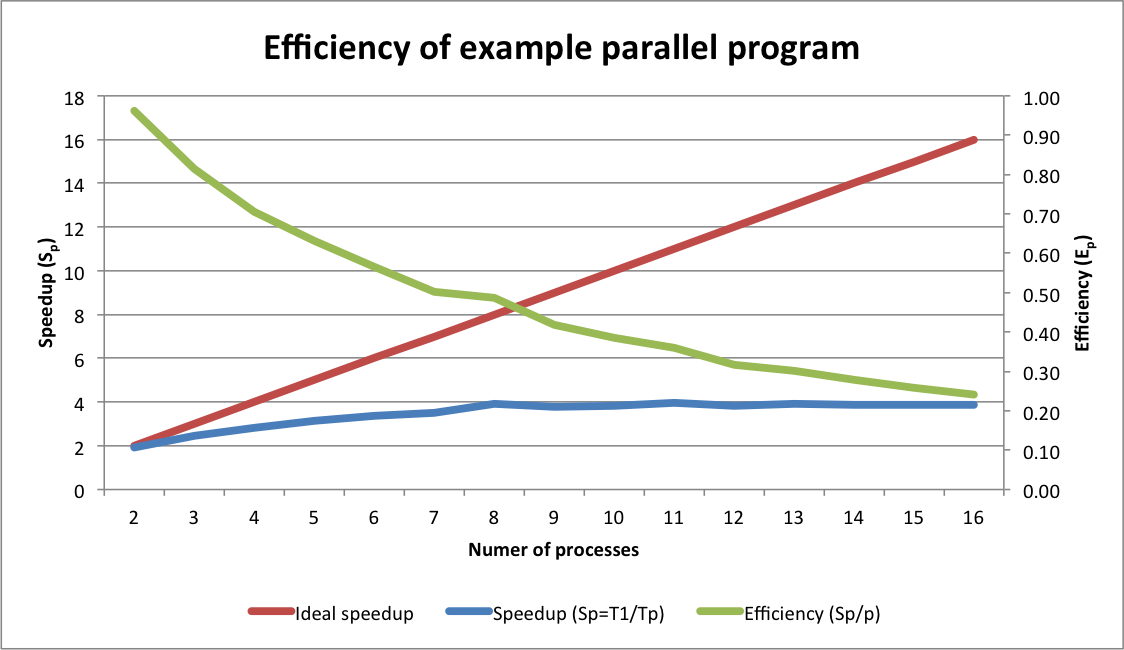
Bedanya Komputasi Paralel dengan Multitasking Apa?

- SISD
- SIMD
- MISD
- MIMD
Apa Aja Aristektur Komputer Parallel?
- Komputer SISD (Single Instruction stream-Single Data stream)
Pada komputer jenis ini semua instruksi dikerjakan terurut satu demi satu, tetapi juga dimungkinkan adanya overlapping dalam eksekusi setiap bagian instruksi (pipelining). Pada umumnya komputer SISD berupa komputer yang terdiri atas satu buah pemroses (single processor). Namun komputer SISD juga mungkin memiliki lebih dari satu unit fungsional (modul memori, unit pemroses, dan lain-lain), selama seluruh unit fungsional tersebut berada dalam kendali sebuah unit pengendali.

- Komputer SIMD (Single Instruction stream-Multiple Data stream)
Pada komputer SIMD terdapat lebih dari satu elemen pemrosesan yang dikendalikan oleh sebuah unit pengendali yang sama. Seluruh elemen pemrosesan menerima dan menjalankan instruksi yang sama yang dikirimkan unit pengendali, namun melakukan operasi terhadap himpunan data yang berbeda yang berasal dari aliran data yang berbeda pula.
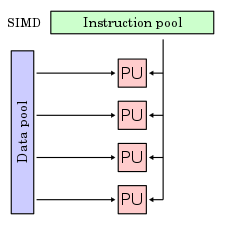
Sebagai contoh kita ingin mencari angka 27 pada deretan angka yang terdiri dari 100 angka, dan kita menggunakan 5 processor. Pada setiap processor kita menggunakan algoritma atau perintah yang sama, namun data yang diproses berbeda. Misalnya processor 1 mengolah data dari deretan / urutan pertama hingga urutan ke 20, processor 2 mengolah data dari urutan 21 sampai urutan 40, begitu pun untuk processor-processor yang lain. Beberapa contoh komputer yang menggunakan model SIMD adalah ILLIAC IV, MasPar, Cray X-MP, Cray Y-MP, Thingking Machine CM-2 dan Cell Processor (GPU).
- Komputer MISD (Multiple Instruction stream-Single Data stream)
Komputer jenis ini memiliki n unit pemroses yang masing-masing menerima dan mengoperasikan instruksi yang berbeda terhadap aliran data yang sama, dikarenakan setiap unit pemroses memiliki unit pengendali yang berbeda. Keluaran dari satu pemroses menjadi masukan bagi pemroses berikutnya. Belum ada perwujudan nyata dari komputer jenis ini kecuali dalam bentuk prototipe untuk penelitian.
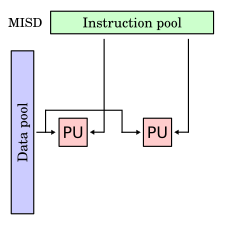
Sebagai contoh, dengan menggunakan kasus yang sama pada contoh model SIMD namun cara untuk menyelesaikannya yang berbeda. Pada MISD jika pada komputer pertama, kedua, ketiga, keempat dan kelima sama-sama mengolah data dari urutan 1-100, namun algoritma yang digunakan untuk teknik pencariannya berbeda di setiap processor. Sampai saat ini belum ada komputer yang menggunakan model MISD.
- Komputer MIMD (Multiple Instruction stream-Multiple Data stream)
Pada sistem komputer MIMD murni terdapat interaksi di antara n pemroses. Hal ini disebabkan seluruh aliran dari dan ke memori berasal dari space data yang sama bagi semua pemroses. Komputer MIMD bersifat tightly coupled jika tingkat interaksi antara pemroses tinggi dan disebut loosely coupled jika tingkat interaksi antara pemroses rendah.
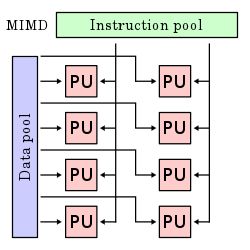
Pada Multiple Instruction, Multiple Data biasanya menggunakan banyak processor dengan setiap processor memiliki instruksi yang berbeda dan mengolah data yang berbeda. Namun banyak komputer yang menggunakan model MIMD juga memasukkan komponen untuk model SIMD. Beberapa komputer yang menggunakan model MIMD adalah IBM POWER5, HP/Compaq AlphaServer, Intel IA32, AMD Opteron, Cray XT3 dan IBM BG/L.
Apa Itu Message Passing Interface?
MPI adalah sebuah standard pemrograman yang memungkinkan pemrogram untuk membuat sebuah aplikasi yang dapat dijalankan secara paralel. Proses yang dijalankan oleh sebuah aplikasi dapat dibagi untuk dikirimkan ke masing – masing compute node yang kemudian masing – masing compute node tersebut mengolah dan mengembalikan hasilnya ke komputer head node. Untuk merancang aplikasi paralel tentu membutuhkan banyak pertimbangan – pertimbangan diantaranya adalah latensi dari jaringan dan lama sebuah tugas dieksekusi oleh prosesor.

- Menulis kode paralel secara portable,
- Mendapatkan performa yang tinggi dalam pemrograman paralel, dan
- Menghadapi permasalahan yang melibatkan hubungan data irregular atau dinamis yang tidak begitu cocok dengan model data paralel.
Sedangkan Parallel Virtual Machine?
Adalah paket software yang mendukung pengiriman pesan untuk komputasi parallel antar komputer. PVM dapat berjalan diberbagai macam variasi UNIX atau pun windows dan telah portable untuk banyak arsitektur seperti PC, workstation, multiprocessor dan superkomputer.
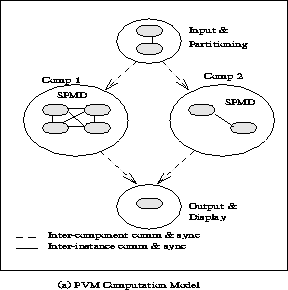
Salah aturan main yang penting dalam PVM adalah adanya mekanisme program master dan slave/worker. Programmer harus membuat Kode master yang menjadi koordinator proses dan Kode slave yang menerima, menjalankan, dan mengembalikan hasil proses ke komputer master. Kode master dieksekusi paling awal dan kemudian melahirkan proses lain dari kode master. Masing-masing program ditulis menggunakan C atau Fortran dan dikompilasi dimasing-masing komputer. Jika arsitektur komputer untuk komputasi paralel semua sama, (misalnya pentium 4 semua), maka program cukup dikompilasi pada satu komputer saja. Selanjutnya hasil kompilasi didistribusikan kekomputer lain yang akan menjadi node komputasi parallel. Program master hanya berada pada satu node sedangkan program slave berada pada semua node.

- Buat file hostfile yang berisi daftar node komputer dan nama user yang akan dipakai untuk komputasi parallel. Bila nama user pada semua komputer sama misalnya nama user riset pada komputer C1, C2,C3 dan C4, maka hostfile ini boleh tidak ada. Hostfile ini dapat digunakan bila nama user di masing-masing komputer berbeda.
- Daftarkan IP masing-masing komputer pada file /etc/hosts/hosts.allow dan /etc/hosts/hosts.equiv.
- Penambahan dan penghapusan host secara dinamis dapat dilakukan melalui konsole PVM. Bila IP tidak didefinisikan pada hostfile¸ cara ini dapat digunakan.
- Jalankan PVM daemon pada setiap mesin dalam cluster
- Jalankan program master pada master daemon
- Master daemon akan menjalankan proses slave.
Bagaimana Perkembangan Komputasi Pararel di Indonesia?
Usaha untuk membangun infrastruktur mesin paralel sudah dimulai sejak era 90-an, meski belum pada tahap serius dan permanen. Namun untuk pemrograman paralel sudah sejak awal menjadi satu mata-kuliah wajib di banyak perguruan tinggi terkait. Baru pada tahun 2005 dimulai pembuatan infrastruktur mesin paralel permanen, misalnya yang dikembangkan oleh Grup Fisika Teoritik dan Komputasi di P2 Fisika LIPI.

Didorong oleh perkembangan pemrograman paralel yang lambat, terutama terkait dengan sumber daya manusia (SDM) yang menguasainya, mesin paralel LIPI ini kemudian dibuka untuk publik secara cuma-cuma dalam bentuk LIPI Public Cluster (LPC). Saat ini LPC telah dikembangkan lebih jauh menjadi gerbang komputasi GRID di Indonesia dengan kerjasama global menjadi IndoGRID.
DISTRIBUTED PROCESSING
Pengertian Distributed Processing
Distributed data processing (DDP) system merupakan bentuk yang sering digunakan sekarang sebagai perkembangan dari time sharing system. Bila beberapa sistem komputer yang bebas tersebar yang masing-masing dapat memproses data sendiri dan dihubungkan dengan jaringan telekomunikasi, maka istilah time sharing sudah tidak tepat lagi. DDP system dapat didefinisikan sebagai suatu sistem komputer interaktif yang terpencar secara geografis dan dihubungkan dengan jalur telekomunikasi dan seitap komputer mampu memproses data secara mandiri dan mempunyai kemampuan berhubungan dengan komputer lain dalam suatu sistem.
Contoh Sistem Pengolahan Data terdistribusi
- Internet
- Jaringan komputer dan aplikasi yang heterogen.
- Mengimplementasikan protokol internet.
- Intranet
- Jaringan yang teradminitrasi secara lokal.
- Terhubung ke internet melalui firewall.
- Menyediakan layanan internet dan eksternal.
- Mobile Computing ( Sistem Komunikasi telepon seluler)
- Menggunakan frekuensi radio sebagai media transmisi
- Perangkat dapat bergerak kemanapun asal masih terjangkau dengan frekuensinya
- Dapat menghandle/dihububngkan dengan perangkat lain
- Sistem Telepon
- ISDN atau yang biasa disebut jaringan telpon tetap (dengan kabel).
- PSTN jaringan telepon/telekomunikasi yang semuanya digital.
- Network File System (NTFS)
- WWW
Contoh Impementasi Distributed Data Processing System
Aplikasi facebook.Com yang biasa anda gunakan untuk bersosialisai dengan saudara, kawan dan orang di seluruh dunia melalui internet. Bila kita lihat aplikasi tersebut, database tidak didistribusikan, tetapi proses sistem dan penggunaan fungsi-fungsi atau feature pada sistem terpisah-pisah prosesnya tidak satu proses saja dalam satu waktu. Pada waktu tertentu ada orang yang sedang isi status, dan mungkin di waktu yang sama ada sedang mencari teman, ada yang mengupload foto dan sebagainya. Tampak disini beberapa proses pada sistem terdistribusi pada setiap client yang berbeda.
Pada penggunaan aplikasi pembayaran / transaksi online pada suatu perusahaan, misalnya saja tiket pesawat terbang. Aplikasi tersebut juga contoh dari aplikasi pengolahan data terdistribusi, dimana data pembayaran ada tersimpan di database bank, sementara data tiketnya tersimpan di database server maskapai yang menyediakan aplikasi tiket online tersebut. Jadi dapat dikatakan bila aplikasi yang digunakan menggunakan database yang terpisah tidak satu database saja, maka dapat dikatakan itu adalah aplikasi pengolahan data terdistribusi atau dikenal juga dengan distributed data processing system.
Pengantar Thread Programming
Dalam pemrograman komputer, sebuah thread adalah informasi terkait dengan penggunaan sebuah program tunggal yang dapat menangani beberapa pengguna secara bersamaan. Dari program point-of-view, sebuah thread adalah informasi yang dibutuhkan untuk melayani satu pengguna individu atau permintaan layanan tertentu. Jika beberapa pengguna menggunakan program atau permintaan bersamaan dari program lain yang sedang terjadi, thread yang dibuat dan dipelihara untuk masing-masing proses. Thread memungkinkan program untuk mengetahui user sedang masuk didalam program secara bergantian dan akan kembali masuk atas nama pengguna yang berbeda. Salah satu informasi thread disimpan dengan cara menyimpannya di daerah data khusus dan menempatkan alamat dari daerah data dalam register. Sistem operasi selalu menyimpan isi register saat program interrupted dan restores ketika memberikan program kontrol lagi.
Sebagian besar komputer hanya dapat mengeksekusi satu instruksi program pada satu waktu, tetapi karena mereka beroperasi begitu cepat, mereka muncul untuk menjalankan berbagai program dan melayani banyak pengguna secara bersamaan. Sistem operasi komputer memberikan setiap program “giliran” pada prosesnya, maka itu memerlukan untuk menunggu sementara program lain mendapat giliran. Masing-masing program dipandang oleh sistem operasi sebagai suatu tugas dimana sumber daya tertentu diidentifikasi dan terus berlangsung. Sistem operasi mengelola setiap program aplikasi dalam sistem PC (spreadsheet, pengolah kata, browser Web) sebagai tugas terpisah dan memungkinkan melihat dan mengontrol item pada daftar tugas. Jika program memulai permintaan I / O, seperti membaca file atau menulis ke printer, itu menciptakan thread. Data disimpan sebagai bagian dari thread yang memungkinkan program yang akan masuk kembali di tempat yang tepat pada saat operasi I / O selesai. Sementara itu, penggunaan bersamaan dari program diselenggarakan pada thread lainnya. Sebagian besar sistem operasi saat ini menyediakan dukungan untuk kedua multitasking dan multithreading. Mereka juga memungkinkan multithreading dalam proses program agar sistem tersebut disimpan dan menciptakan proses baru untuk setiap thread.
Static Threading
Teknik ini biasa digunakan untuk komputer dengan chip multiprocessors dan jenis komputer shared-memory lainnya. Teknik ini memungkinkan thread berbagi memori yang tersedia, menggunakan program counter dan mengeksekusi program secara independen. Sistem operasi menempatkan satu thread pada prosesor dan menukarnya dengan thread lain yang hendak menggunakan prosesor itu.
Mekanisme ini terhitung lambat, karenanya disebut dengan static. Selain itu teknik ini tidak mudah diterapkan dan rentan kesalahan. Alasannya, pembagian pekerjaan yang dinamis di antara thread-thread menyebabkan load balancing-nya cukup rumit. Untuk memudahkannya programmer harus menggunakan protocol komunikasi yang kompleks untuk menerapkan scheduler load balancing. Kondisi ini mendorong pemunculan concurrency platforms yang menyediakan layer untuk mengkoordinasi, menjadwalkan, dan mengelola sumberdaya komputasi paralel.
Sebagian platform dibangun sebagai runtime libraries atau sebuah bahasa pemrograman paralel lengkap dengan compiler dan pendukung runtime-nya.
Dynamic Multithreading
Teknik ini merupakan pengembangan dari teknik sebelumnya yang bertujuan untuk kemudahan karena dengannya programmer tidak harus pusing dengan protokol komunikasi, load balancing, dan kerumitan lain yang ada pada static threading. Concurrency platform ini menyediakan scheduler yang melakukan load balacing secara otomatis. Walaupun platformnya masih dalam pengembangan namun secara umum mendukung dua fitur : nested parallelism dan parallel loops. Nested parallelism memungkinkan sebuah subroutine di-spawned (ditelurkan dalam jumlah banyak seperti telur katak) sehingga program utama tetap berjalan sementara subroutine menghitung hasilnya. Sedangkan parallel loops seperti halnya fungsi for namun memungkinkan iterasi loop dilakukan secara bersamaan.
PEMROGRAMAN CUDA (GRAPHICAL PROCESSING UNIT)
Sebagaimana telah kita ketahui bahwa Cuda adalah platform komputasi paralel dan model pemrograman yang diciptakan oleh perusahaan perangkat keras dunia yaitu NVIDIA. hal ini memungkinkan peningkatan dramatis dalam kinerja komputasi dengan memanfaatkan kekuatan dari Graphics Processing Unit(GPU).
GPU (Graphical Processing Unit) pada awalnya adalah sebuah prosesor yang berfungsi khusus untuk melakukan rendering pada kartu grafik saja, tetapi seiring dengan semakin meningkatnya kebutuhan rendering, terutama untuk mendekati waktu proses yang realtime /sebagaimana kenyataan sesungguhnya, maka meningkat pula kemampuan prosesor grafik tersebut. akselerasi peningkatan teknologi GPU ini lebih cepat daripada peningkatan teknologi prosesor sesungguhnya (CPU), dan pada akhirnya GPU menjadi General Purpose, yang artinya tidak lagi hanya untuk melakukan rendering saja melainkan bisa untuk proses komputasi secara umum.
Penggunaan Multi GPU dapat mempercepat waktu proses dalam mengeksekusi program karena arsitekturnya yang natively parallel. Selain itu Peningkatan performa yang terjadi tidak hanya berdasarkan kecepatan hardware GPU saja, tetapi faktor yang lebih penting adalah cara membuat kode program yang benarbenar bisa efektif berjalan pada Multi GPU.
CUDA merupakan singkatan dari Compute Unified Device Architecture,didefinisikan sebagai sebuah arsitektur komputer parallel, dikembangkan oleh Nvidia. Teknologi ini dapat digunakan untuk menjalankan proses pengolahan gambar, video, rendering 3D, dan lain sebagainya. VGA – VGA dari Nvidia yang sudah menggunakan teknologi CUDA antara lain : Nvidia GeForce GTX 280, GTX 260,9800 GX2, 9800 GTX+,9800 GTX,9800 GT,9600 GSO, 9600 GT,9500 GT,9400 GT,9400 mGPU,9300 mGPU,8800 Ultra,8800 GTX,8800 GTS,8800 GT,8800 GS,8600 GTS,8600 GT,8500 GT,8400 GS, 8300 mGPU, 8200 mGPU, 8100 mGPU, dan seri sejenis untuk kelas mobile (VGA notebook).
Singkatnya, CUDA dapat memberikan proses dengan pendekatan bahasa C, sehingga programmer atau pengembang software dapat lebih cepat menyelesaikan perhitungan yang komplek. Bukan hanya aplikasi seperti teknologi ilmu pengetahuan yang spesifik. CUDA sekarang bisa dimanfaatkan untuk aplikasi multimedia. Misalnya meng-edit film dan melakukan filter gambar. Sebagai contoh dengan aplikasi multimedia, sudah mengunakan teknologi CUDA. Software TMPGenc 4.0 misalnya membuat aplikasi editing dengan mengambil sebagian proces dari GPU dan CPU. VGA yang dapat memanfaatkan CUDA hanya versi 8000 atau lebih tinggi.
Keuntungan dengan CUDA sebenarnya tidak luput dari teknologi aplikasi yang ada. CUDA akan mempercepat proses aplikasi tertentu, tetapi tidak semua aplikasi yang ada akan lebih cepat walaupun sudah mengunakan fitur CUDA. . Hal ini tergantung seberapa cepat procesor yang digunakan, dan seberapa kuat sebuah GPU yang dipakai. Dan bagian terpenting adalah aplikasi apa yang memang memanfaatkan penuh kemampuan GPU dengan teknologi CUDA. Kedepan seperti pengembang software Adobe akan ikut memanfaatkan fitur CUDA pada aplikasi mereka. Jawaban akhir adalah, untuk memanfaatkan CUDA kembali melihat aplikasi software yang ada. Apakah software yang ada memang mampu memanfaatkan CUDA dengan proses melalui GPU secara penuh. Hal tersebut akan berguna untuk mempercepat selesainya proses pada sebuah aplikasi. Dengan kecepatan proses GPU, aplikasi akan jauh lebih cepat. Khususnya teknologi ilmu pengetahuan dengan ramalan cuaca, simulator pertambangan atau perhitungan yang rumit dibidang keuangan. Sedangkan aplikasi umum sepertinya masih harus menunggu.
Paralelisme
Paralelisme (parallelism) lahir dari pendekatan yang biasa dipergunakan oleh para perancang sistem untuk menerapkan konsep pemrosesan konkuren. Teknik ini meningkatkan kecepatan proses dengan cara memperbanyak jumlah modul perangkat keras yang dapat beroperasi secara simultan disertai dengan membentuk beberapa proses yang bekerja secara simultan pada modul-modul perangkat keras tersebut. Secara formal, pemrosesan parallel adalah sebuah bentuk efisien pemrosesan informasi yang menekankan pada eksploitasi dari konkurensi kejadian-kejadian dalam proses komputasi.Pemrosesan paralel dapat terjadi pada beberapa tingkatan (level) proses. Tingkatan tertinggi pemrosesan paralel terjadi pada proses di antara banyak job (pekerjaan) atau pada program yang menggunakan multiprogramming, time sharing, dan multiprocessing.
Multiprogramming kemampuan eksekusi terhadap beberapa proses perangkat lunak dalam sebuah system secara serentak, jika dibandingkan dengan sebuah proses dalam satu waktu, dan timesharing berarti menyediakan pembagian selang waktu yang tetap atau berubah-ubah untuk banyak program. Multiprocessing adalah dukungan sebuah sistem untuk mendukung lebih dari satu prosesor dan mengalokasikan tugas kepada prosesor-prosesor tersebut. Multiprocessing sering diimplementasikan dalam perangkat keras (dengan menggunakan beberapa CPU sekaligus), sementara multiprogramming sering digunakan dalam perangkat lunak. Sebuah sistem mungkin dapat memiliki dua kemampuan tersebut, salah satu di antaranya, atau tidak sama sekali. Pemrosesan paralel dapat juga terjadi pada proses di antara prosedurprosedur atau perintah perintah (segmen program) pada sebuah program.Untuk meningkatkan kecepatan proses komputasi, dapat ditempuh dua cara :
Peningkatan kecepatan perangkat keras.
Komponen utama perangkat keras komputer adalah processor. Meskipun kecepatan processor dapat ditingkatkan terus, namun karena keterbatasan materi pembuatnya, tentu ada suatu batas kecepatan yang tak mungkin lagi dapat dilewati. Karena itu timbul ide pembuatan komputer multiprocessor. Dengan adanya banyak processor dalam satu komputer, pekerjaan bisa dibagi-bagi kepada masing-masing processor. Dengan demikian lebih banyak proses dapat dikerjakan dalam satu saat. Peningkatan kecepatan setiap proses bisa dicapai melalui peningkatan kecepatan perangkat lunak. Kecepatan perangkat lunak sangat ditentukan oleh algoritmanya.
Peningkatan kecepatan perangkat lunak.
Program komputer untuk komputer sekuensial harus menyediakan sederetan operasi untuk dikerjakan oleh prosesor tunggal. Program komputer untuk komputer paralel harus menyediakan sederetan operasi untuk beberapa prosesor untuk dikerjakan secara paralel, termasuk operasi untuk mengatur dan mengitegrasikan prosesor-prosesor yang terpisah tersebut mengerjakan suatu komputasi yang koheren. Kebutuhan akan pembuatan dan pengaturan berbagai aktivitas komputasi paralel menambah dimensi baru proses dari pemrograman komputer. Algoritma untuk problem yang spesifik harus diformulasikan sedemikian rupa, agar menghasilkan aliran operasi paralel yang kemudian akan dieksekusi di prosesor yang berbeda. Karena itu, meskipun arsitektur multiprosesor dan multikomputer mempunyai pontensi yang tinggi untuk meningkatkan kemampuan komputasi, potensi ini akan tercapai melalui pengertian yang baik mengenai bahasa pemrograman paralel dan perancangan algoritma paralel.
Tingkat Paralelisme
Berdasarkan tingkat paralelismenya prosesor paralel dapat dibagi menjadi beberapa tingkat sebagai berikut :
- Komputer Array :
- Prosesor array : beberapa prosesor yang bekerja sama untuk mengolah set instruksi yang sama dan data yang berbeda – beda atau biasa disebut SIMD (Single Instruction-stream Multiple Data)
- Prosesor vektor : beberapa prosesor yang disusun seperti pipeline.
- Multiprosesor, yaitu sebuah sistem yang memiliki 2 prosesor atau lebih yang saling berbagi memori.
- Multikomputer, yaitu sebuah sistem yang memiliki 2 prosesor atau lebih yang masing-masing prosesor memiliki memori sendiri.
Jenis-Jenis Pemrosesan Paralel
Pemrosesan paralel dapat dibagi ke dalam beberapa klasifikasi, sebagai berikut :
- Berdasarkan simetri penjadwalannya, pemrosesan parallel dapat dibagi dalam beberapa jenis:
- a) Asymmetric Multiprocessing (ASMP)
- b) Symmetric Multiprocessing (SMP)
- c) ClusteringPoliteknik Telkom Sistem Komputer
- Berdasarkan aliran instruksi dan datanya, pemrosesan parallel dapat dibagi dalam beberapa jenis:
- a) SISD (Single Instruction on Single Data Stream)
- b) SIMD (Single Instruction on Multiple Data Stream)
- c) MISD (Multiple Instruction on Single Data Stream)
- d) MIMD (Multiple Instruction on Multiple Data Stream)
- Berdasarkan kedekatan antar prosesor, pemrosesan parallel dapat dibagi dalam beberapa jenis:
- a) Multikomputer (Loosely Coupled/ local memory) dengan memori yang terdistribusi
- b) Multiprosesor (Tightly Coupled/ global memory) dengan memori yang dapat digunakan bersama (shared memory)
– https://fskita.com/2018/07/13/distributed-data-processing-system-berserta-contoh-implementasi/
– https://rachmadpropaganda.wordpress.com/2011/04/01/online-communication/
